

 Microsoft Fabric
Microsoft FabricData modeling has long been relegated to the technical corners of organizations, viewed as a necessary evil that slows down delivery and adds complexity to projects. However, this perspective fundamentally misunderstands what data modeling truly represents and the transformative value it can deliver to enterprise organizations. When we strip away the technical jargon and focus on business outcomes, data modeling emerges as one of the most powerful tools for driving operational efficiency, reducing costs, and accelerating time to market.
Understanding What Data Modeling Really Is
Before we can discuss the return on investment of data modeling, we must first dispel the common misconception of what it actually entails. Data modeling is not merely the creation of technical diagrams or database schemas that only engineers can understand. Instead, it represents a comprehensive approach to understanding and documenting your organization’s business model through three interconnected components: the business model itself, the data structures that support it, and the shared vocabulary that enables effective communication across teams.
The business model component addresses fundamental questions about what your organization does and what data truly matters for achieving those objectives. The data model layer focuses on how to structure and organize this critical information for maximum utility and accessibility. Finally, the vocabulary component ensures that everyone in the organization speaks the same language when discussing data concepts, eliminating the confusion and miscommunication that plague so many data initiatives.

Consider a simple example: “We sell shoes online.” This business model translates into data concepts like active customers, product categories, and inventory management. The vocabulary includes terms like orders, items, SKUs, and the relationships between these entities. When properly modeled, these concepts become universally understood across the organization, from marketing teams analyzing customer behavior to supply chain managers tracking inventory levels.
The Hidden Costs of Poor Data Modeling
Organizations that neglect data modeling often fail to recognize the cumulative costs of their decision until it’s too late. As Joe Reis aptly noted, “A lack of a data model is still a data model, albeit a crappy one.” The symptoms of poor data modeling manifest in ways that many organizations have come to accept as normal business operations, but they represent significant hidden costs that compound over time.
Here are just some of the pain points that creep in when not enough attention is devoted to data modeling:
- Duplicate or unused data
- Multiple names for common objects
- Poor self-service
- Lack of discoverability
- Meetings instead of documentation
- Poor data quality
- Businesses lack trust in the data (and data team)
Duplicate and unused data become commonplace when teams lack a clear understanding of what information already exists within the organization. Multiple names for common objects create confusion and inconsistency, leading to endless debates about which version of the truth is correct. Poor self-service capabilities force business users to rely heavily on data teams for basic information requests, creating bottlenecks and reducing overall productivity.
“Rather than expanding to address data quality issues, teams typically steal bandwidth from value-added work to handle fixes and maintenance”
The lack of discoverability means that valuable data assets remain hidden, forcing teams to recreate information that already exists elsewhere in the organization. When documentation is absent or inadequate, important business logic gets trapped in meetings and tribal knowledge, making it difficult for new team members to contribute effectively. These issues ultimately erode business trust in both the data and the data team, creating a low-trust environment characterized by blame, shadow BI implementations, and constant firefighting.
Data Modeling as a Collaborative Team Sport
One of the most persistent myths about data modeling is that it’s exclusively a technical activity confined to the data team. This misconception likely stems from decades of legacy tooling that kept data models locked away in specialized software on individual workstations. However, the modern era of cloud-based enterprise software has eliminated these barriers, enabling data models to serve as powerful collaboration tools for entire organizations.
Effective data modeling happens where business expertise meets technical implementation. While people often assume that modeling occurs in isolation within the data team, the reality is that the most valuable modeling work happens in conference rooms, collaborative sessions, and cross-functional meetings where business knowledge gets translated into structured data concepts. The data team serves as the driver of this process, providing technical expertise and implementation capabilities, while business teams act as navigators, ensuring that the resulting models accurately reflect operational realities and strategic objectives.
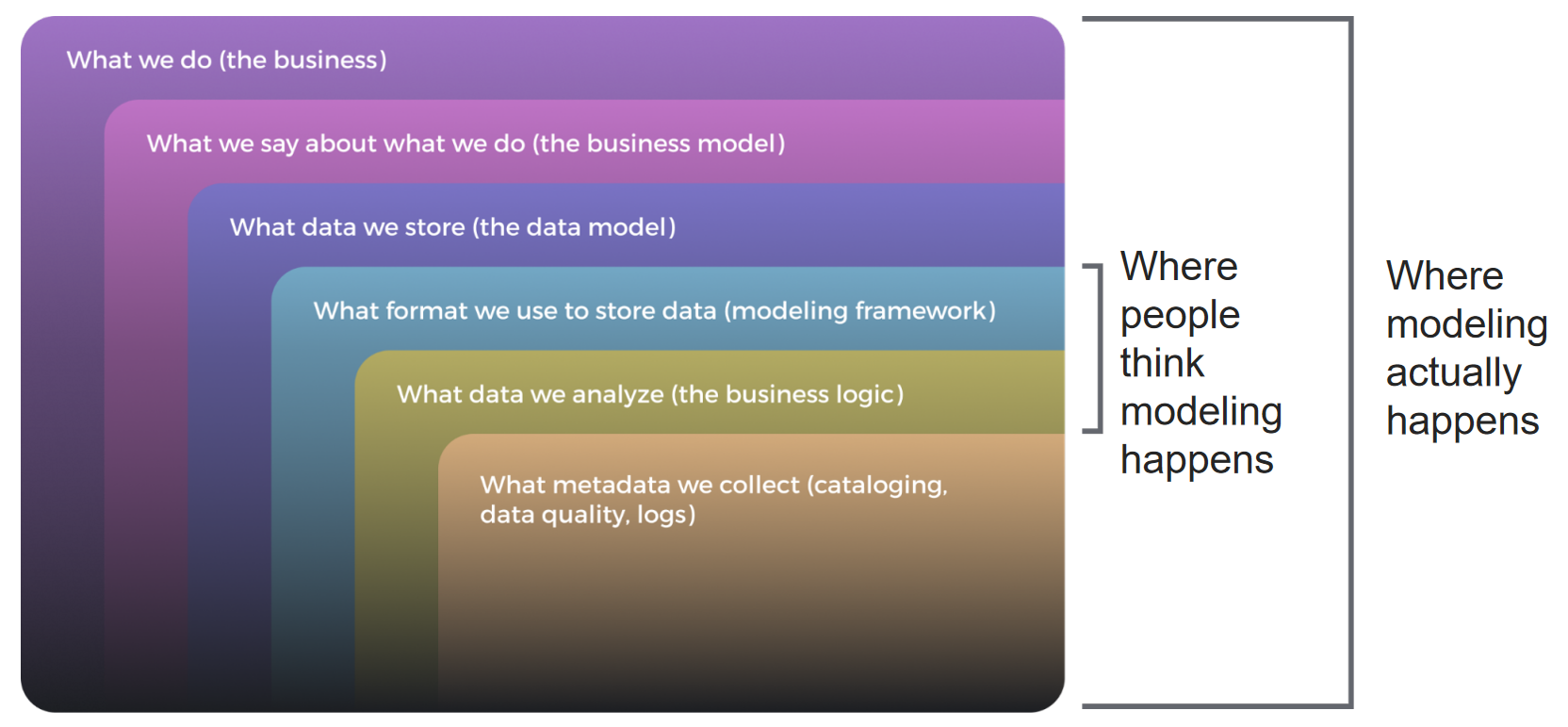
This collaborative approach yields benefits that extend far beyond improved data quality. When business and technical teams work together to create shared understanding, they develop consensus around the business model itself, making it easier to identify opportunities for reuse across projects and enabling more effective self-service capabilities. The resulting acceleration in time to market for analytics and reporting initiatives often surprises organizations that have grown accustomed to lengthy development cycles.
Demonstrating Value Through Business Metrics
The engineering team wants to invest in data modeling, while business stakeholders demand faster delivery dates. Fortunately, there’s a path to satisfying both constituencies by speaking the language that resonates with budget committees and executive decision-makers: business metrics and return on investment calculations. Let’s quickly summarize some KIPs we’ll be discussing below:
- Initial investment – the upfront cost of starting a project. E.g., development, testing, hardware, software expenses.
- Expected lifetime – how long a project is expected to deliver value post-delivery.
- Ex. in years: dashboard 1-2, data mart 3-5, enterprise data platform 5-10.
- Operating costs – costs to maintain once delivered, multiplied by expected lifetime. E.g., Full-time Employees (FTEs), licenses, cloud infrastructure, etc.
- Total Cost of Ownership (TCO) – total project cost over the expected lifetime, including development and operating costs.
- Expected benefit – value that delivering the project will bring to the company. Business stakeholders own this metric.
- Return on investment (ROI) – the monetary value of an investment versus its cost.
- ROI = (Expected benefit – TCO) / TCO
- Opportunity cost – the loss of other alternatives when one alternative is chosen.
Every data project requires consideration of the entire lifecycle, not just initial delivery costs. The initial investment includes upfront development, testing, hardware, and software expenses. Organizations must also estimate operating costs, such as those for full-time employees, licenses, and cloud infrastructure, multiplied by the expected lifetime of the solution. A dashboard targeted at a specific business initiative might provide value for one to two years, while a data mart could serve the organization for three to five years, and an enterprise data platform might deliver benefits for five to ten years or more.
The Total Cost of Ownership (TCO) encompasses both initial investment and lifetime operating costs, offering a comprehensive view of project expenses. On the benefits side, business stakeholders own the Expected Benefit metric, which represents the value that delivering the project will bring to the company. Together, these components enable calculation of the Return on Investment using the formula: ROI = (Expected Benefit – TCO) / TCO.
A Practical Example: The Power of Comparative Analysis
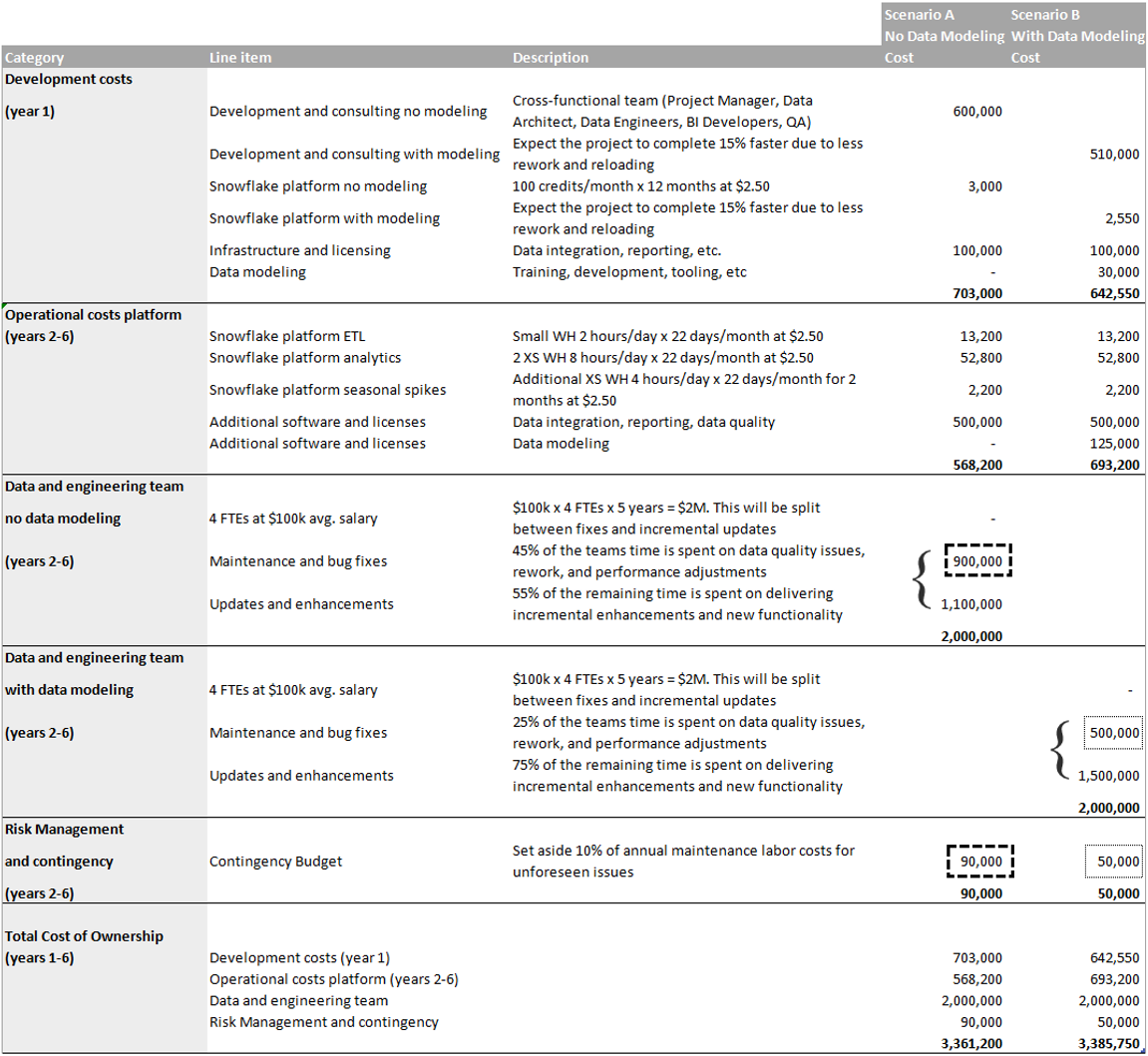
To illustrate the impact of data modeling on project ROI, consider a medium-scale data mart project expected to take one year to complete and provide productivity gains for five years thereafter. By comparing two scenarios—one with data modeling and one without—we can quantify the benefits in terms that business leaders understand and appreciate.
The spreadsheet used in the example below can be downloaded and modified to fit your project.
Scenario B, which includes data modeling, incorporates additional upfront costs for training, workshops with business stakeholders, software and tooling, and design activities. However, these investments yield significant returns through improved development efficiency. Better requirements gathering and business alignment help avoid rework, reloading, and re-testing, resulting in a conservative 15% improvement in development costs and timelines.
Perhaps most importantly, the total cost of the data and engineering team remains constant between scenarios—only the allocation changes. This represents what I call “the secret that hides in plain sight.” Rather than expanding to address data quality issues, teams typically steal bandwidth from value-added work to handle fixes and maintenance. In our example, the difference between maintenance and bug fixes between the two scenarios equals roughly one full-time employee, a quarter of the data team working exclusively on fixes in the scenario without data modeling.
The Tangible and Intangible Benefits of Better Data Quality
The benefits of data modeling extend beyond immediate cost savings to create compounding value over time. When projects include proper data modeling from the outset, they generate additional value through incremental changes and enhancements throughout their lifecycle. Since the total bandwidth of data team time allocated to enhancements is greater in the data modeling scenario due to less time spent on fixes, more resources can be devoted to value-added work that maximizes business benefits.
These improvements create what economists call opportunity cost benefits—resources that would have been wasted on rework and fixes can instead be invested in meaningful alternatives. Over the lifecycle of a project, this momentum builds to generate truly astonishing gains in productivity and achievement.
In our practical example, the scenario with data modeling yields a 5% greater return on investment thanks to improved efficiencies and added value. More impressively, when we calculate the ROI of data modeling itself by comparing the total expected benefits with and without modeling, we find that every dollar spent on data modeling generates a return of nearly 30%.
While quantifiable metrics provide compelling arguments for data modeling investments, the most important benefits often can’t be captured on any balance sheet. The transformation from a low-trust to a high-trust data environment represents a fundamental shift in organizational culture that drives long-term success.
In low-trust environments, teams resort to shadow BI implementations, spend excessive time on fixes rather than features, and operate in a climate of blame and finger-pointing. Business users must constantly question whether data is usable before making decisions, leading to paralysis and missed opportunities. Conversely, high-trust environments are characterized by single sources of truth, a focus on feature development rather than firefighting, and collaborative relationships between business and technical teams.

With better planning and alignment and less time spent fixing data quality issues, business teams have no cause to blame or pressure the data team for inaccurate information. Data quality fosters trust, respect, and a collaborative spirit that drives organizations forward in lockstep, creating a virtuous cycle of improved performance and increased confidence in data-driven decision-making.
Overcoming Organizational Barriers
Despite the clear benefits of data modeling, many well-intentioned organizations struggle with implementation due to persistent myths and organizational barriers. Common misconceptions include the belief that data modeling is exclusively for technical teams, represents a one-time effort, or is only relevant for large projects and organizations. These myths often stem from outdated understanding of modern data modeling tools and approaches.
More challenging are the genuine organizational barriers that require strategic thinking to overcome. Engineering teams often lack familiarity with business metrics, making it difficult to communicate value in terms that resonate with stakeholders. Decentralized data ownership creates fragmentation and inconsistency that undermines unified modeling efforts. The absence of top-down data strategy leaves individual teams to pursue their own approaches, resulting in silos and missed opportunities for collaboration.
Successful data modeling adoption requires a strategic approach that builds momentum through quick wins while addressing systemic challenges. Rather than attempting to tackle everything at once, organizations should identify their most pressing data pain points and focus on small, targeted modeling exercises that deliver immediate value.
The key is to prioritize projects with high-impact potential, enabling teams to generate measurable improvements in data quality and operational efficiency. These quick wins serve as tangible proof of concept for the broader benefits of data modeling, building stakeholder confidence and support for future initiatives. By showcasing faster report generation, enhanced data reliability, and reduced manual reconciliation efforts, data teams can demonstrate value in terms that business users understand and appreciate.
A clever approach to initiating these conversations involves asking business experts to confirm something you know to be incorrect or contentious. Nothing ensures participation like giving someone a chance to correct the narrative and demonstrate their domain expertise. Once engaged, these experts become valuable allies in the data modeling process, contributing their deep understanding of business processes and requirements.
The Path Forward: Data Modeling as Organizational Strategy
Data modeling represents far more than a technical exercise—it’s a strategic initiative that can transform how organizations operate, collaborate, and compete. When properly implemented, data modeling creates a shared language that enables better communication, accelerates decision-making, and unlocks the full value of data assets.
The return on investment calculations provide compelling evidence for data modeling initiatives; however, the true value lies in the cultural transformation that occurs when organizations adopt collaborative data practices. As Ralph Waldo Emerson observed, “There needs but one wise man in a company and all are wise, so rapid is the contagion.” Data modeling provides the foundation for this organizational wisdom, creating capabilities that compound over time and drive sustained competitive advantage.
For organizations ready to embark on this journey, the message is clear: data modeling is a team sport that requires collaboration between business and technical teams. The data team drives the process with technical expertise and implementation capabilities, while business teams navigate with domain knowledge and strategic insight. Together, they can create data models that serve as powerful tools for organizational alignment, operational efficiency, and strategic decision-making.
The question is not whether your organization can afford to invest in data modeling, but whether it can afford not to. In an increasingly data-driven world, the organizations that master collaborative data modeling will have a significant advantage over those that continue to operate with fragmented, siloed approaches. The time to start is now, and the path forward begins with recognizing that data modeling is not just about data—it’s about transforming how your organization thinks, communicates, and succeeds in the digital age.



