








 Microsoft Fabric
Microsoft Fabric
SqlDBM is increasingly recognized as a linchpin in modern data ecosystems, especially for teams embracing powerful cloud data platforms like Snowflake and Databricks. These platforms have revolutionized how data is stored, processed, and accessed, bringing elastic computing and near-infinite scalability to enterprises of every size. But alongside their many benefits, they also introduce a level of complexity that can overwhelm organizations still relying on fragmented, manual approaches to database design. SqlDBM offers a unifying thread in this environment — one that streamlines schema management, fosters cross-functional collaboration, and lays a stronger foundation for AI/ML adoption.
Snowflake has become a go-to solution for data warehousing in the cloud, known for separating compute from storage and making it possible to spin up multiple independent “virtual warehouses.” In many ways, Snowflake democratizes data analysis: more teams can run queries without worrying about concurrency bottlenecks or capacity issues. Yet the very ease of spinning up new compute resources can fuel siloed, ad hoc data projects. You might find that one department has created a separate Snowflake database with only partial documentation, and another department is using a different naming convention entirely. As these data silos multiply, confusion sets in. People begin to question the validity of certain columns or the definitions behind certain metrics. That’s precisely where SqlDBM’s centralized data modeling approach proves essential. By offering an authoritative blueprint for every table, view, and relationship, it anchors all those independent Snowflake environments to a single, well-documented schema. This alignment sharply reduces the risk of duplication or conflicting definitions. It also means that when a new project spins up, there is no guesswork about how to structure or name tables, what constraints or primary keys are standard, or which definitions have already been approved.
Databricks has similarly changed the analytics landscape through its Lakehouse architecture. By combining the flexibility of data lakes with the performance and reliability of data warehouses, Databricks empowers teams to handle batch and streaming data at scale, run sophisticated data transformations, and seamlessly integrate with machine learning workflows. Despite these advances, Databricks also brings its own modeling challenges. You can store near-infinite amounts of raw or semi-structured data in systems like Delta Lake, but a large portion of that data may remain opaque if nobody has mapped out its relationships or documented the transformations that turn raw files into polished datasets. As data scientists comb through parquet files and structured tables in Databricks, they often need clarity on how each dataset is intended to be joined with the next or which columns are reliably populated. SqlDBM closes that gap by serving as a structured design layer: it gives your data engineers and architects a way to formalize those relationships and create robust, maintainable schemas, even in a file-based environment. They can reference each pipeline in the model, ensuring data arrives with well-documented constraints and relationships, so that the broader team sees a coherent picture of how each dataset fits into the analytics puzzle.
When you combine Snowflake’s warehousing strengths with Databricks’ advanced data engineering and machine learning capabilities, you open the door to powerful, hybrid approaches to analytics. Some organizations move aggregated data from Databricks pipelines into Snowflake for highly concurrent BI reporting. Others orchestrate data flows back and forth, choosing the best environment for each specific workload. But those multi-platform workflows are only as reliable as the design that underpins them. Without a tool like SqlDBM, teams can end up chasing definitions and re-creating schemas in one place or the other, hoping they match. A single source of truth for all design artifacts means you no longer have to guess if the table name in Databricks is spelled differently than in Snowflake or if a certain column in your dimension table has the same data type in both environments. SqlDBM helps ensure that designs remain consistent and accessible, no matter where your data ultimately resides or how it is consumed.
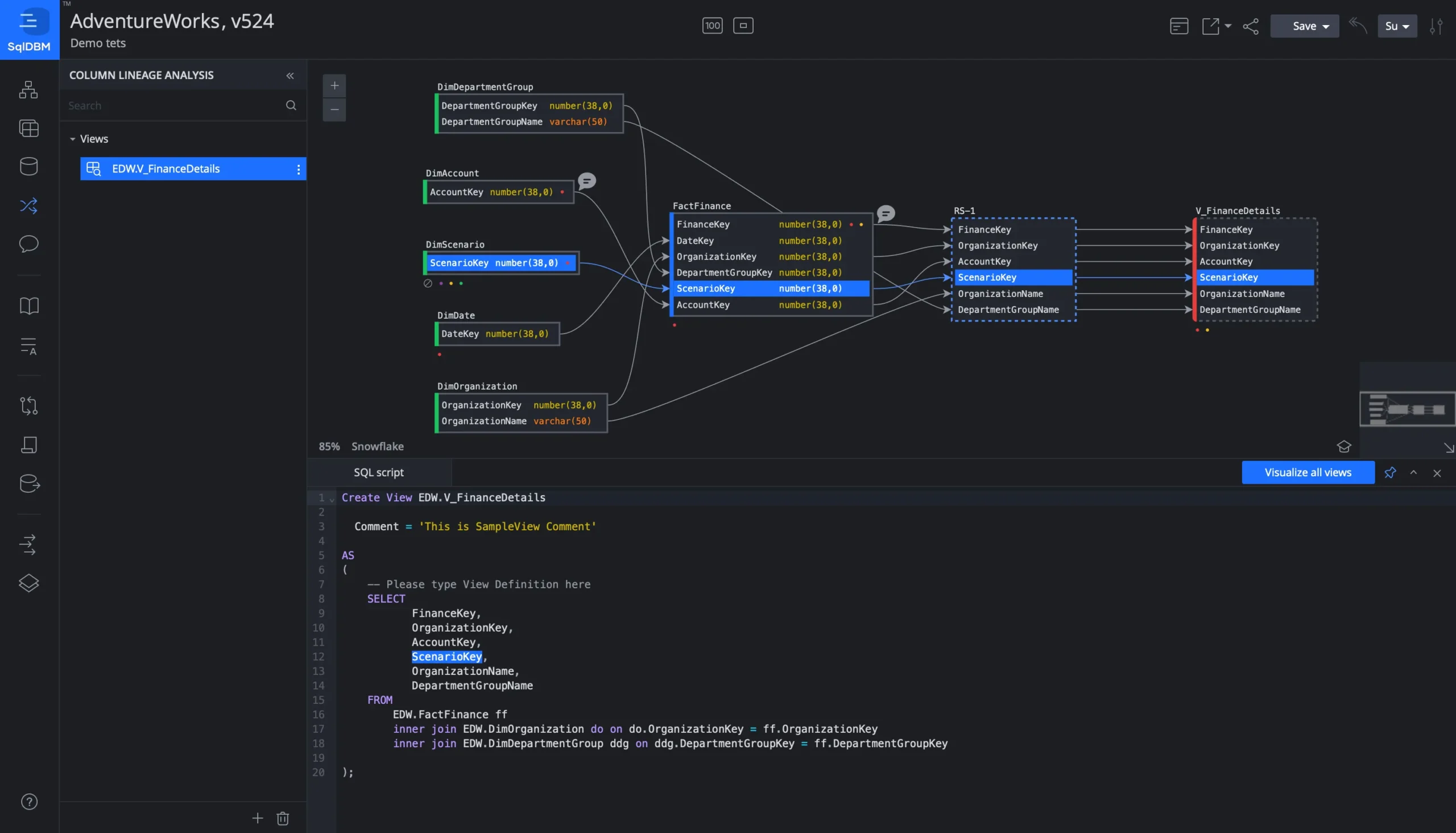
This consistent, documented design environment has become especially critical for AI/ML adoption. Machine learning typically demands a great deal of data exploration and transformation. Data scientists need to locate relevant features, understand their distributions, and decide whether to combine certain fields into new predictive variables. That process can bog down or turn into guesswork if the data environment is messy and poorly documented. In an ideal scenario, data scientists come to a single repository — SqlDBM — and see precisely how data is structured, which relationships exist between tables, and what each column means. They can immediately spot which fields align with the target variables they are trying to predict, track potential sources of missing values, and ensure that the data types fit the algorithms they plan to run. The more clarity they have, the less time they spend wrangling and the more they can focus on building accurate models.
This clarity extends further when we talk about Databricks and advanced ML pipelines. Databricks provides robust machine learning runtimes where you can train models at scale and experiment with notebooks. Data scientists and ML engineers often rely on feature stores or curated feature tables to keep their workflows organized. But if the design behind those feature stores is not aligned with the overarching data schema, confusion and duplication become inevitable. One team might define a customer’s “latest purchase date” in a slightly different way than another, or store it in a different format. If nobody is documenting it at the design level, these variations won’t come to light until the model outputs start to diverge or produce contradictory insights. When the entire organization treats SqlDBM as the canonical reference, those definitions stay consistent, and data lineage remains traceable, from ingestion through to the final model outputs.
Trust in data is central to any AI/ML initiative. If your business partners are skeptical about the lineage or transformation steps behind the results, they won’t be confident making strategic moves based on those predictions. SqlDBM bolsters that trust by enforcing rigorous design practices. Everyone can see the version history of each schema, review the commentary from data architects or engineers discussing why a certain column was changed, and confirm that the transformations going into a model meet compliance or governance standards. This ability to track and trace information across Snowflake, Databricks, and beyond assures stakeholders that everything is above board, consistent, and validated. Machine learning models become more than just black-box algorithms because the data pipeline feeding them is transparent and well-structured. For companies operating in heavily regulated environments, this level of governance also helps meet audit and compliance requirements. Auditors often want to know not just how the data is being stored but also how it flows and is transformed. SqlDBM automatically documents these relationships and structures, making audits far less stressful.
Data scientists themselves benefit from these documented, up-to-date schemas in other ways. When exploring new features, they can comment directly within SqlDBM, highlighting potential data quality concerns or requesting certain changes from data engineers. That collaborative feedback loop shortens iteration cycles and reduces the risk of implementing features that do not match real-world business definitions. If the model needs a refined definition of “annual revenue,” the data scientist can tag the data steward or architect right in the design, ensuring that the new attribute is formally recognized and integrated into the broader schema. This synergy between robust modeling and ML experimentation saves days or even weeks of trial and error. It keeps advanced analytics initiatives firmly grounded in clean, validated data instead of letting them drift into one-off transformations or side datasets that nobody else fully understands.
BI Developers and Analysts working in Snowflake also reap the rewards. Because SqlDBM supports forward and reverse engineering, they can generate scripts to create or alter tables directly in Snowflake based on the final, approved design. Similarly, they can reverse-engineer existing databases to create an updated model in SqlDBM whenever needed. This is a critical step in large teams or enterprises that must frequently reconcile production schemas with their design artifacts. Instead of relying on word-of-mouth or incomplete documentation, they can refresh the model from the actual Snowflake instance, capturing every column, relationship, constraint, and view. That model then serves as a reference for business intelligence, ensuring that queries against Snowflake rely on well-documented fields. By the time analysts or business stakeholders open up a BI dashboard, they know it’s constructed on top of a carefully designed schema that has gone through thorough validation and commentary. The definitions in their visualizations match what appears in the underlying tables, building a cycle of consistent, data-driven collaboration.
On the data engineering side, Databricks workflows can similarly be aligned with the SqlDBM model. Engineers who design ingestion pipelines for streaming data or build complex transformations in Databricks notebooks often manage enormous sets of raw logs or event data. This raw information must be shaped into refined tables that analytics and AI/ML teams can consume. Using SqlDBM, data engineers can articulate how that raw data maps into well-defined tables — specifying primary keys, relationships, and naming conventions — and ensure those transformations remain consistent, even if done in multiple notebooks or jobs. Whenever changes are needed, say to add a new column or restructure a table for performance reasons, they can propose the design change in SqlDBM, tag relevant stakeholders, and validate the schema before deploying the new pipeline to Databricks. This process saves them from the dreaded scenario where one part of the pipeline is updated while other components remain in the dark, leading to broken transformations or conflicting outputs.
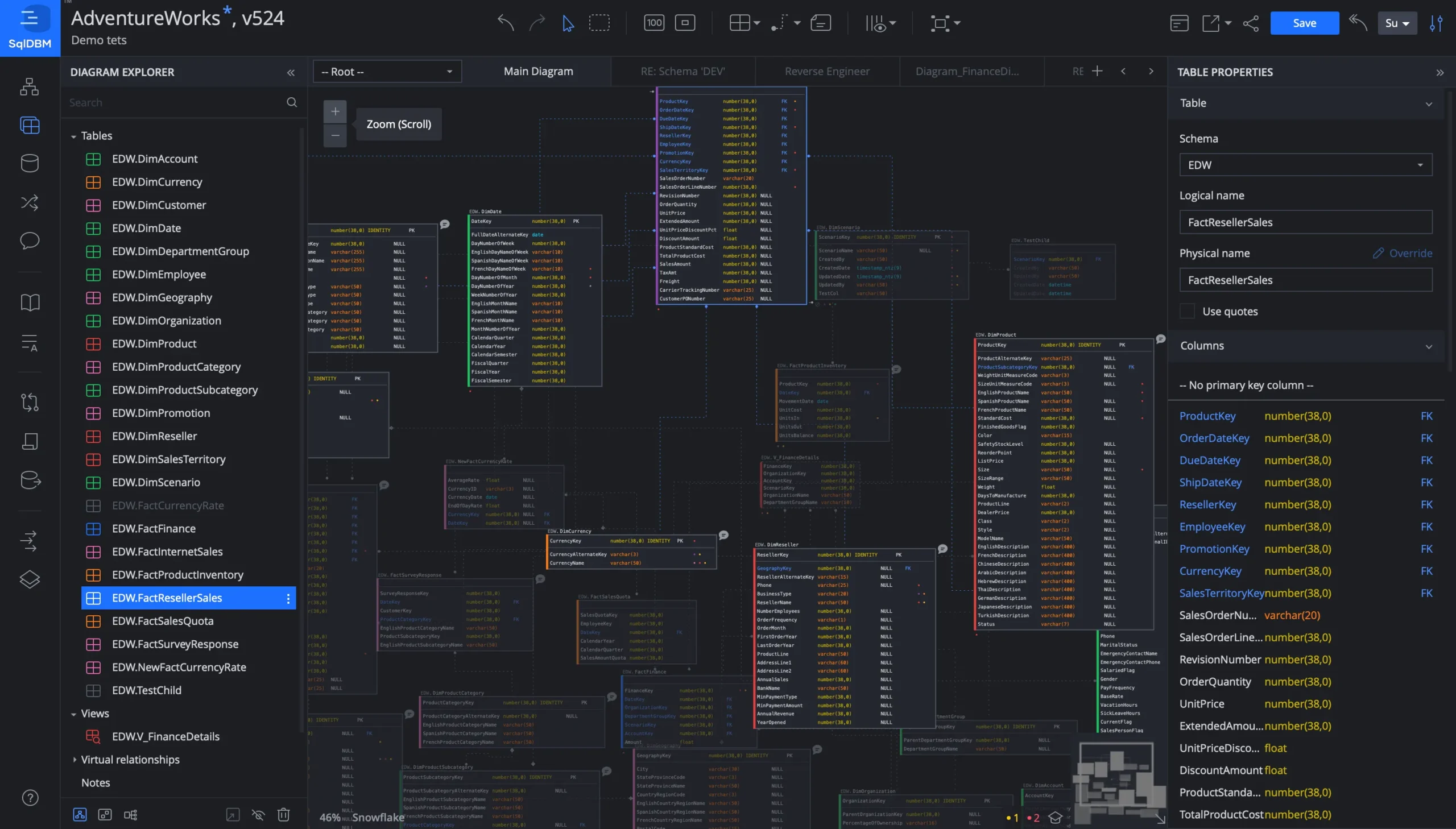
That synergy among different roles is the true power of SqlDBM in the modern data stack. Data Architects, Data Stewards, BI Developers, AI/ML Practitioners, and Business Consumers all interface with it in slightly different ways. However, each interaction builds upon a single version of the truth, which is especially important for organizations that plan to scale their machine-learning capabilities. As more data scientists and engineers come on board, clarity around schema evolution and data lineage only becomes more vital. Siloed environments might work in the earliest days of a small startup, but they become untenable once you have multiple teams working in parallel, each pushing changes to Snowflake or running advanced queries in Databricks. SqlDBM keeps track of those changes, documents the reasons behind them, and minimizes the risk of accidental overrides or destructive merges. Its version control features, combined with real-time collaboration, mimic the best practices of software development — like Git — for data design.
All these efficiencies lead to tangible results in AI/ML development cycles. Data scientists can speed up the feature engineering process because they no longer have to reverse-engineer table relationships by trial and error. They have a deeper insight into the lineage of each data attribute, which is critical for explaining model outputs and maintaining transparency. Less time is wasted second-guessing data definitions or hunting through old Slack messages to figure out who changed a specific table last quarter. Cross-functional teams find it easier to hold short design discussions and confirm the new additions in a matter of hours, rather than hosting extended email chains or offline meetings that could drag on for days. By the time the model is trained and an executive team sees the results, the entire pipeline — from raw data in Databricks to aggregated data in Snowflake — can be traced back through a well-defined, collaborative design. That’s a level of confidence that spares data teams from frantic last-minute justifications whenever a business leader asks, “Where exactly did you get that data, and how can we trust it?”
Speed and error reduction are only part of the overall equation. There’s also a cultural transformation. Having a single, shared data modeling tool instills a sense of discipline and transparency throughout the organization. Engineers understand that they need to document their changes in SqlDBM, which encourages them to think more carefully about naming conventions or the design rationale. Data Stewards can embed governance policies directly into the model, marking sensitive fields that might require masking or restricted access in Snowflake or Databricks. BI Developers appreciate that they can rely on consistent definitions when building dashboards or metrics, and the machine learning teams know that the data feeding their models has been thoroughly vetted. Over time, all these roles begin to operate with a far more cohesive mindset. Data-driven decision-making flows more naturally because the underlying data pipeline is stable, consistent, and easy to evolve.
Organizations that have adopted SqlDBM alongside Snowflake and Databricks often notice an acceleration in innovation. Rather than being locked into isolated projects or waiting for one group to finish their documentation, cross-functional teams can spin up new analytics or ML initiatives more confidently. Because Snowflake allows for near-instant scaling of compute and Databricks simplifies big data transformations, the remaining bottleneck often lies in the clarity of design. Once SqlDBM removes that barrier, the synergy between advanced platforms and robust schema management allows for rapid iteration. Teams can test new product features or marketing strategies, harness machine learning insights, and pivot quickly when the data suggests a new direction. That agility is exactly what modern enterprises need if they want to keep pace with ever-changing market conditions and consumer demands.
In many cases, an organization’s biggest hurdle is not so much adopting the technology as it is shifting the workflow habits of the people who use it. Transitioning to a unified data modeling culture requires executives, managers, and individual contributors to see SqlDBM as a mission-critical part of their workflow, not just “another tool.” Once they grasp how it tangibly improves everything from pipeline stability to AI/ML accuracy, the adoption tends to follow naturally. Leadership can reinforce this practice by requiring that every new table, view, or feature store definition first be checked into SqlDBM, so the design is always up to date before moving on to the technical implementation. Such policies ensure that data changes remain visible and validated rather than spontaneously appearing in a production environment.
As these workflows solidify, teams find they spend fewer cycles recovering from schema errors, pipeline breaks, or misunderstood definitions. Instead, they allocate more resources to creative problem-solving and advanced analytics. Data professionals can focus on tasks that genuinely require their expertise, such as optimizing transformations in Databricks or applying sophisticated algorithms to large, curated datasets, rather than chasing down the reasons a column name changed. For leadership and business stakeholders, all of this translates into quicker, more precise insights, the ability to trust AI/ML predictions, and an organizational culture that sees data as a strategic asset rather than a chaotic sprawl.
SqlDBM, Snowflake, and Databricks each bring separate strengths to the table, but it’s the seamless integration of all three that elevates an enterprise’s data capabilities to new heights. Snowflake’s elasticity and concurrency, Databricks’ data engineering and machine learning prowess, and SqlDBM’s robust, unified modeling combine into a comprehensive ecosystem. It’s an ecosystem that fosters agility and trust, keeping data accessible yet controlled, flexible yet carefully documented. As the appetite for AI-driven insights grows, so too does the need for a design-first approach that ensures data is well-organized, governed, and ready for machine learning at scale. SqlDBM stands out as a platform that can anchor that approach, harmonizing the roles of Data Architects, Engineers, Analysts, Stewards, and AI/ML practitioners into a single, coherent data pipeline.
The result is a data organization that can genuinely call itself “modern” — not just because it uses cloud platforms or advanced analytics, but because it has orchestrated the entire data lifecycle from ingestion to insights in a coordinated, transparent manner. Ultimately, the synergy here is what transforms raw data into innovative solutions, from dynamic dashboards to production-grade ML models. And that is the promise of leveraging SqlDBM in tandem with Snowflake and Databricks: the promise of data clarity, operational resilience, and a culture that is fully prepared to harness AI/ML for competitive advantage. It’s a shift that redefines how data is perceived in the organization, turning it from a source of headaches and doubt into a wellspring of actionable, transformative power.



